
AI 不只会做应用:用 AI 协作完成一份资料结构 RFC 与多语言实作
以 Rangeable RFC 为例,从问题抽象、演算法选型、语意定义到 Ruby / Swift 参考实作,记录 AI 如何参与更深入的技术研究与设计。

背景
前几周为了 Re-Design 我的 个人网站 ,直上了 Claude Code Max 后来又用 AI x Google Apps Script 做了一个个人桌上 Dashboard Deck 把旧的 iPhone 变废为宝;这周开始把目标转向之前做的开源专案,用 AI 重构原本手搓的程式码,优化效率、补充文件、补足测试。
TL;DR
先用 AI 重构了几个开源专案的应用层面,因而得到启发也让他做做深入的 Foundation 资料结构设计。
Linkyee— Your Own Link Page
A fully customized, 100% free, open-source LinkTree alternative — deployed straight to GitHub Pages.
第一个优化的是之前做的 类 — Linktree 免费开源自架版,用 AI 重整了一下架构、多设计几个主题、多做几个内建 Plugin、新增 Design AI Skill 让使用者方便客制化、补充本地测试环境。
ZMediumToMarkdown
Download Medium posts as clean Markdown, preserving structure, images, links, code blocks, and common embeds for plain Markdown or Jekyll workflows.
帮你把文章的所有内容包含图片、内嵌程式码、Youtube 连结…全部下载转换成 Markdown、图片也会一起下载放到 ./assets 。
第二个是我一直在使用、维护了四年多的专案 — 「下载并转换 Medium 文章成 Markdown 格式」的工具,因为后期我几乎只把 Medium 当成文章编辑器后台,主力是透过这工具把原文下载转换后传到我的 自架网站 。
这个专案是我的网站跟 Medium 之间的重要桥梁,不能断;当初第一版开发的时候花了我大量的时间跟精力,这几年也都在修修补补一些小问题,但是很久没有整个重新检视设计与优化了。
一样是先从 AI 优化应用开始,除了请他重构+补测试原本手搓的渲染逻辑外;还有补强 Medium Cloudflare Anti-bot 流程,让使用者可以在遇到 Medium 阻挡爬虫时能优雅地从 Chrome 登入后自动获取 Cookies 然后自动执行。
mcp-medium-reader
最后还请 AI 建了 Medium.com 文章 Reader MCP 服务。
主要是基础的转换服务 ZMediumToMarkdown 都做好了,MCP 只是一层 Wrapper 呼叫它来做就能达成。
解决的问题是 AI 如 ChatGPT, Codex, Claude, Claude Code 贴给他 Medium 文章时很容易被 Medium 的 Cloudflare Anti-bot 阻挡爬取内容,以至于 AI 无法直接读取文章,就算能也是读取 HTML,不是 AI 友善的 Markdown。
mcp-medium-reader _能让你的 AI 穿透封锁并且读取 Markdown 版本的 Medium 文章,节省 Token 的同时又能提升 AI 理解性。*
带标签区间集合问题
当年在做 ZMediumToMarkdown 的时候有遇到 这个 Foundation 资料结构设计(算法)问题 ,那时候没有多余的精力也没有能力解决,但现在有 AI 了,想想可以尝试用 AI 解决这个问题。
案例一 — Medium 渲染问题
Medium.com 的 GraphQL API 回传的文章内容资料如下格式:
{
"text": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.",
"markups": [
{
"type": "A",
"start": 169,
"end": 207,
"href": "https://zhgchg.li/posts/f6713ba3fee3/",
"anchorType": "LINK",
"userId": null,
"linkMetadata": null,
"__typename": "Markup"
},
{
"type": "STRONG",
"start": 0,
"end": 29,
"href": null,
"anchorType": null,
"userId": null,
"linkMetadata": null,
"__typename": "Markup"
},
{
"type": "EM",
"start": 15,
"end": 55,
"href": null,
"anchorType": null,
"userId": null,
"linkMetadata": null,
"__typename": "Markup"
},
{
"type": "STRONG",
"start": 69,
"end": 88,
"href": null,
"anchorType": null,
"userId": null,
"linkMetadata": null,
"__typename": "Markup"
}
]
}
翻译成白话文:
[0,14] STRONG = Lorem ipsum dol
[15,29] STRONG + EM = or sit amet, co
[30,55] EM = nsectetur adipiscing elit,
[56,68] normal = sed do eiusm
[69,88] STRONG = od tempor incididunt
[89,168] normal = ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercit
[169,207] A = ation ullamco laboris nisi ut aliquip e
预期渲染结果:

注意:Medium 原始资料的 end 语意需依实际 API 定义转换;本文后续以 Rangeable RFC 的 closed interval 语意说明。
问题
-
区间叠加 同一区间可以是多个状态叠加,例如 [15,29] 是 STRONG + EM
-
区间交错 极端状况下使用者可能设定交错的样式,[0,29] 是 STRONG / [15,55] 是 EM
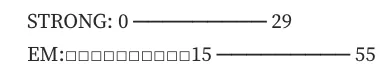
- 区间连续合并 资料可能给 [0,12] 是 STRONG / [12,29] 是 STRONG 需要合并成 [0,29] 是 STRONG
区间叠加、区间连续合并还算好处理,最麻烦的是区间交错闭合处理,不能直接照 index 渲染,会变成 **AA_AA**BBB_ ,需要自己处理开闭变成 **AA_AA_**_BBB_ 才会是正确的 Markdown。
iOS 开发者如果有用过 NSAttributedString attributes 也是一样的问题,只是 Apple Foundation 帮我们做好区间合并跟叠加处理了。
当时也是搞了很久想了老半天,书到用时方恨少,平时刷题太少遇到实际要用的时候没武器可用;那时候是用最暴力的 walkthrough 解决,结果正确只是效能跟程式码很可怕。
关联的 LeetCode 题型
- Merge Intervals
56. Merge Intervals
57. Insert Interval
用途: 合并 STRONG [0,12], STRONG [13,29] -> STRONG [0,29]。
- Sweep Line
253. Meeting Rooms II
731. My Calendar II
732. My Calendar III
1094. Car Pooling
1851. Minimum Interval to Include Each Query
用途:
STRONG [0,29]
EM [15,55]
A [169,207]
to
0 open STRONG
15 open EM
30 close STRONG
56 close EM
169 open A
208 close A
- Difference Array,但不是纯数字差分
370. Range Addition
1109. Corporate Flight Bookings
1094. Car Pooling
用途: 维护 active markup set
- Interval Split / Segment Construction
用途:
STRONG [0,29]
EM [15,55]
to
[0,14] STRONG
[15,29] STRONG + EM
[30,55] EM
其他用到的题型、资料结构:
-
Event Sorting
-
Interval Partition / Segment Split
-
Stack / Parentheses Matching
-
Binary Search
-
Ordered Set / LinkedHashSet
-
Canonicalization
案例二 — AVPlayer Cache 区段问题
上面 Medium 遇到的区间问题其实我之前也遇过类似的,在开发「 AVPlayer 本地边播边 Cache 时 」也有遇到。
因为串流资料是不连续的,一份 Size: 1000 的 Data,AVPlayer 可能会要求 [0,100] [300–500] [150, 200]… 之间的不连续或是交错资料。
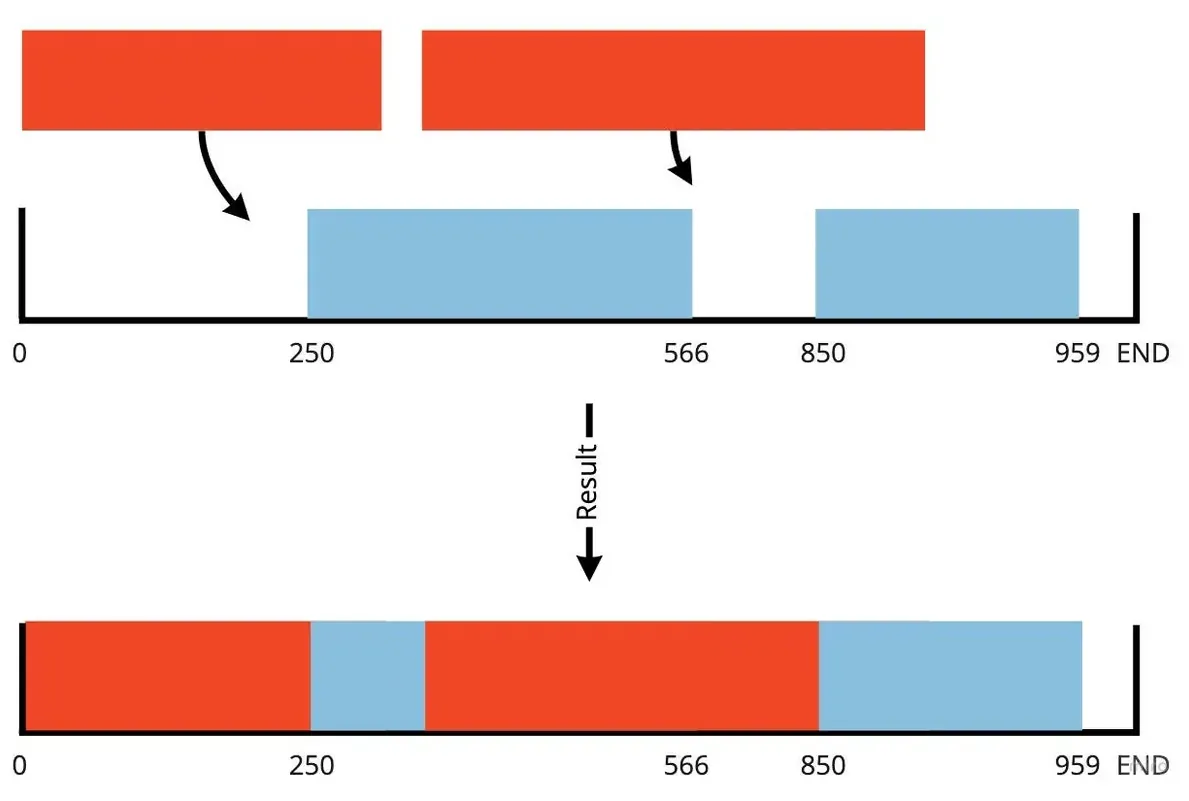
以上图为例,假设 目前已有资料区段: [250,566] [850,959] ,理想上:
-
AVPlayer 询问 [0,300] 时: [0,249] 从远端拿、[250,300] 从本地拿
-
AVPlayer 询问 [350, 920] 时: [350,566] 从本地拿、[567,849] 从远端拿、[850,920] 从本地拿
当时一样遇到区间计算问题 — Covered / Uncovered Interval Query ,不过比 Medium 问题简单因为这边是 Binary Data 0 跟 1 的区别而已,只需要计算结果。
当时也是暂时没解,因为光开发 AVPlayer 边播放边缓存的功能就花大半时间了;加上当时场景是音讯,档案本身就不大; 直接先走区间没资料就全拿覆盖的方式 — 细节请参考原文章「 AVPlayer 本地 Cache 实作攻略|使用 AVAssetResourceLoaderDelegate 节省 iOS 音乐串流流量 」 。
整体协作流程
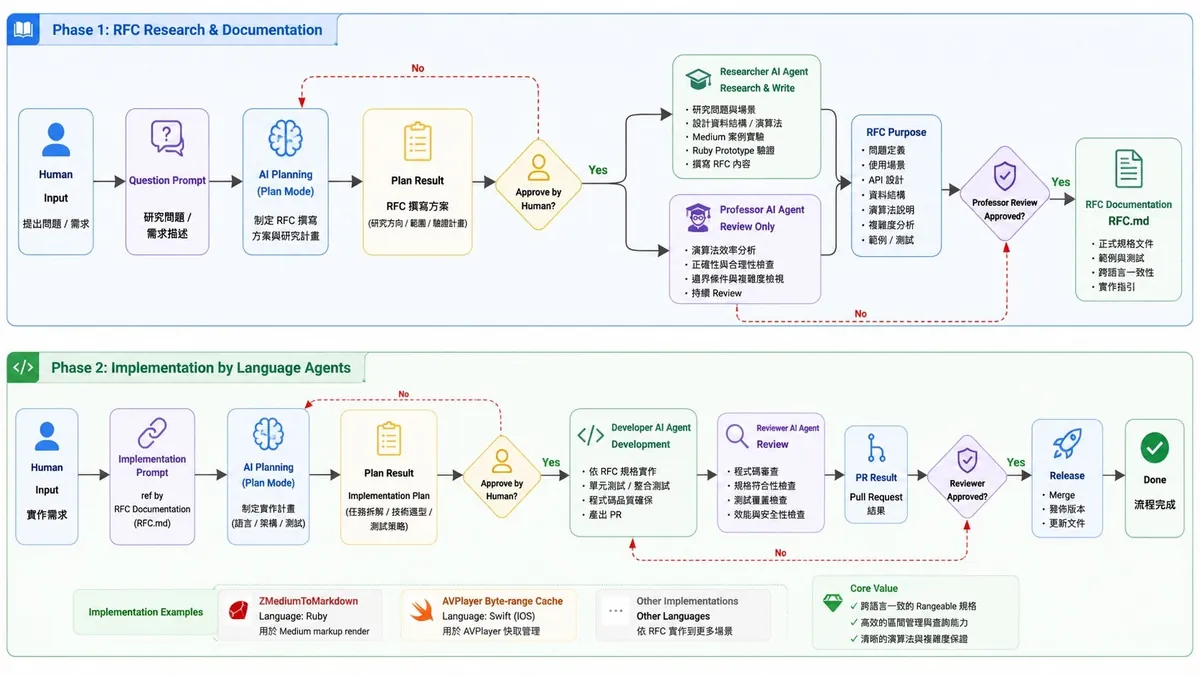
用 AI 实现 Foundation 资料结构设计
工具
-
Claude Code Max
-
Effort: Max
-
Model: Opus 4.7
流程
-
先请 AI Plan Mode 起草研究 RFC 撰写方案
-
请 AI 开始研究并且有两个 Agent 身份:一位是研究生专门负责研究与撰写 RFC、另一位是教授只负责专注在 Review 算法效率与合理性。(Review 直到 Approve)
-
研究生可以先以 Medium 案例为实验、用 Ruby 开发看看
-
最终产出 RFC.md 文件
-
交由其他 Agent 实现到各种语言 (我 ZMediumToMarkdown 是 Ruby / AVPlayer 是 iOS Swift 问题)
1. AI 研拟资料结构 RFC — Rangeable RFC
Prompt (Plan Mode):
/plan
請使用英文,參考英文論文研究,研擬一份 RFC 實作文件,之後會交付讓其他語言可以遵循這份文件實現,研擬期間可以使用 Ruby 作為實驗語言。
你需要研究所有資料結構與演算法,找出一套時間與空間效率最平衡的算法達成需求。
工具名稱:Rangeable
功能:計算泛型物件組合的連續與不連續集合。
範例:
var strings:Rangeable<String> = []
strings.insert(Strong(), start: 2, end: 5) // 2-5 Strong
strings.insert(Strong(), start: 3, end: 7) // 3-7 Strong
strings.insert(Strong(), start: 9, end: 11) // 9-11 Strong
strings.insert(Italic(), start: 3, end: 8 ) // 3-8 Italic
// Usage:
Strong().getRange(from: strings) -> [{2,7},{9-11}]
Italic().getRange(from strings) -> [{3,8}]
//
strings[4].objs -> [Strong(), Italic()]
strings[8].objs -> [Italic()]
strings[10].objs -> [Strong()]
//
請注意 Strong, Italic 本身也是泛型,這裡只是舉例
//
實際研擬 RFC 時請用 sub-agent 一個是研究生負責研究人實現方式與撰寫 RFC、另一個是教授以學術或更深入的演算法為主回頭 Review 研究生 Agent 的產出;如果被教授 Agent 駁回就重新研究撰寫 RFC。
可以先建立 ./RubyRangeable Ruby 的實現 和 ./SwiftRangeable Swift 的實現
你可以盡情消耗 Token 與花費資源做研究。
//
提供一個實際應用場景:../ZMediumToMarkdown 中的 MarkupStyleRender.rb
目前會解析 Medium GraphQL 回傳的 Paragraphs
{"id": "f30dc1c4fe6c_19", "name": "b2ba", "type": "BQ", "href": null, "layout": null, "metadata": null, "text": "A notification webhook is an endpoint you create on your server.\n通知型 Webhook 是你在自己伺服器上建立的一個端點(endpoint)。", "hasDropCap": null, "dropCapImage": null, "markups": [{"type": "EM", "start": 0, "end": 104, "href": null, "anchorType": null, "userId": null, "linkMetadata": null, "__typename": "Markup"}], "__typename": "Paragraph", "codeBlockMetadata": null, "iframe": null, "mixtapeMetadata": null},
{"id": "f30dc1c4fe6c_20", "name": "f2e8", "type": "BQ", "href": null, "layout": null, "metadata": null, "text": "This webhook endpoint receives HTTP POST requests from App Store Connect.\n這個 Webhook 端點會接收來自 App Store Connect 的 HTTP POST 請求。", "hasDropCap": null, "dropCapImage": null, "markups": [{"type": "EM", "start": 0, "end": 126, "href": null, "anchorType": null, "userId": null, "linkMetadata": null, "__typename": "Markup"}], "__typename": "Paragraph", "codeBlockMetadata": null, "iframe": null, "mixtapeMetadata": null},
{"id": "f30dc1c4fe6c_21", "name": "1725", "type": "BQ", "href": null, "layout": null, "metadata": null, "text": "The POST requests describe important events about your app.\n這些 POST 請求會描述與你的 App 相關的重要事件。", "hasDropCap": null, "dropCapImage": null, "markups": [{"type": "EM", "start": 0, "end": 89, "href": null, "anchorType": null, "userId": null, "linkMetadata": null, "__typename": "Markup"}], "__typename": "Paragraph", "codeBlockMetadata": null, "iframe": null, "mixtapeMetadata": null},
{"id": "f30dc1c4fe6c_22", "name": "3e9d", "type": "BQ", "href": null, "layout": null, "metadata": null, "text": "Use the webhooks notifications endpoint to configure the notifications for events happening to your apps.\n你可以使用 Webhook 通知端點,來設定當你的 App 發生各種事件時所要接收的通知。", "hasDropCap": null, "dropCapImage": null, "markups": [{"type": "EM", "start": 0, "end": 151, "href": null, "anchorType": null, "userId": null, "linkMetadata": null, "__typename": "Markup"}], "__typename": "Paragraph", "codeBlockMetadata": null, "iframe": null, "mixtapeMetadata": null},
然後依照 start, end 渲染出 Markdown,可是目前沒有算法所以是用巡迴填補的方法。
2. 方案确定后研究生 Agent 开始研究 -> 产出第一版 RFC
3. 教授 Agent 开始 Review -> REJECTED
主因是教授认为 RFC 还有 6 个 MUST-FIX ,也就是不修不能通过的规格/演算法正确性问题。
4. 研究生 Agent 回头研究修改 -> 产出第二版 RFC
5. 教授 Agent 重新 Review -> APPROVED
6. Done
-
花费时间:约 1 hr 30 mins
-
花费 Token:178K (约占 Claude Code Max 5 hr 可用额度的 30%)
Rangeable RFC
TL;DR
Rangeable<Element>是一个用来管理「元素在哪些整数闭区间内生效」的通用资料结构。它可以把同一元素重叠或相邻的区间自动合并,并支援查询某个 index 上有哪些元素 active,以及输出某段范围内的 open / close transition events。它原本是为了解决 Medium Markdown markup render 问题,例如判断某个字元同时套用了STRONG、EM、LINK哪些样式;但同样 也能套用在 Calendar、游戏状态、Genome annotation、AVPlayer byte-range cache 等场景 。核心价值是把「区间合并、active set 查询、边界事件产生」抽象成一个 deterministic、跨语言一致、适合 Ruby / Swift 实作的规格。
以下 RFC 细节除非很有兴趣不然可以直接略过。这边也是直接用 AI 翻译总结的。
Rangeable<Element> 是一个「 把元素对应到多段整数闭区间,并能快速查询某个位置有哪些元素生效 」的通用资料结构。
它解的不是单纯的 Range 问题,而是给我很多个 (元素, start, end) ,我要能:
-
查某个元素有哪些合并后的区间
-
查某个 index 上有哪些元素 active
-
查某段范围内有哪些 open / close 边界事件
RFC 明确定义 Rangeable 是一个 language-neutral、generic、integer-coordinate、closed-interval set container,元素必须可 Hash,比对以 value equality 为准。它支援 getRange 、 r[i].objs 、 transitions 三种查询。
主要动机
这份 RFC 起源于 ZMediumToMarkdown 的 Medium markup render 问题。
Medium paragraph 内会有像这样的 markups:
STRONG: [2, 5]
STRONG: [3, 7]
EM: [4, 10]
目前 render 时需要逐字扫描,判断每个字元上有哪些 tag active,例如 bold、italic、link、code 等。RFC 里提到原本做法会把 markups 转成 TagChar ,依照 startIndex 排序,然后每个字元线性扫过所有 tags,最坏会到 O(L · m) 。 Rangeable 想把这件事抽象化成通用容器,让 renderer 只要 insert markups,再用 r[i].objs 或 transitions 查询即可。
RFC 也把这个问题扩展到其他场景,例如:
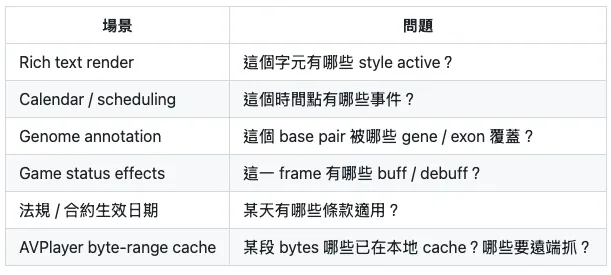
RFC 明确指出共通问题是:给定很多 (eᵢ, lᵢ, hᵢ) ,查某个位置 i 时,要回传所有满足 l ≤ i ≤ h 的元素。
核心概念翻译
1. Rangeable<Element>
可以想成:
Element -> [ClosedRange<Int>]
但它不是普通 Dictionary,因为它会:
-
自动合并同一元素的重叠区间
-
自动合并相邻区间
-
保留元素第一次插入顺序
-
支援快速查询某个 index 上 active 的 elements
-
支援输出 open / close transition events
例如:
insert(STRONG, 2, 5)
insert(STRONG, 3, 7)
最后会变成:
STRONG -> [(2, 7)]
因为 [2,5] 和 [3,7] 重叠。
API 重点
RFC 定义的主要 API 如下。
insert(e, start, end)
insert(e: Element, start: Int, end: Int)
效果是:
R(e) = canonicalize(R(e) ∪ [start, end])
也就是把新区间加入元素 e 的既有区间集合,然后做 canonicalize:合并所有重叠或相邻的区间并排序。 start > end 必须丢出 InvalidIntervalError ;重复 insert 相同内容是 idempotent,不应改变结果,也不应增加 version。
r[i].objs / activeAt(index:)
r[i] -> Slot
r.activeAt(index: i) -> Slot
回传某个 index 上 active 的 elements。
例如:
insert(Strong, 2, 5)
insert(Italic, 3, 7)
查询:
r[3].objs
结果是:
[Strong, Italic]
查询复杂度目标是:
O(log M + r)
其中 M 是所有元素合并后的 interval 数量总和, r 是该位置实际回传的元素数。
getRange(of:)
getRange(of e) -> [(Int, Int)]
回传某个元素目前合并后的 canonical ranges。
例如:
insert(Strong, 2, 4)
insert(Strong, 5, 7)
因为 [2,4] 和 [5,7] 在整数座标上相邻,所以结果是:
[(2, 7)]
RFC 明确要求回传的 intervals 必须排序、互不重叠、也不相邻。
transitions(over:)
transitions(over: ClosedRange<Int>) -> [TransitionEvent]
回传一段范围内的 open / close 边界事件。
例如:
insert(Strong, 2, 5)
insert(Italic, 3, 7)
则 transitions 会是:
[
(2, open, Strong),
(3, open, Italic),
(6, close, Strong),
(8, close, Italic)
]
注意 close event 的位置是 hi + 1 ,因为外部语意是闭区间 [lo, hi] ,但 sweep-line 内部用「第一个不再 active 的位置」当 close coordinate。RFC 明确说明 transitions(over: lo..hi) 会包含 hi + 1 的 close event,方便处理右边界。
区间语意
1. end 是 inclusive
这份 RFC 非常明确: insert(e, start: a, end: b) 表示闭区间 [a, b] , b 本身也包含在 active range 里。
也就是:
insert(Strong, 2, 5)
代表:
2, 3, 4, 5 都 active
不是 [2, 5) 。
RFC 选择 inclusive 的原因包括:
-
符合 Medium markup / ZMediumToMarkdown 的历史资料模型
-
比较符合「这个字元是否 active」的人类直觉
-
整数相邻合并可以写成
hi + 1 == lo -
单点区间
[k, k]可以自然表示一个有效位置
2. 相邻区间要合并
在整数座标上:
[2, 4] + [5, 7] => [2, 7]
因为 4 和 5 之间没有任何整数位置可以表示「不 active」。RFC 要求同一个元素的整数相邻区间必须合并。
但:
[2, 4] + [6, 7] => [(2, 4), (6, 7)]
因为中间有 5 这个 gap。
3. start == end 是合法 singleton interval
insert(e, 5, 5)
代表只有 index 5 active。RFC 要求这是合法且非空的区间。
4. start > end 必须丢错
insert(e, 10, 5)
不能自动反转成 [5,10] ,也不能 silent normalize。RFC 要求必须丢出 InvalidIntervalError ,而且 container 状态不能改变。
Element equality 语意
Rangeable 判断两个 element 是否同一个元素,是看语言原生的 value equality。
Ruby:
eql? + hash
Swift:
Hashable / Equatable
所以:
Link("a") 和 Link("a") 會被視為同一個元素,區間會合併
Link("a") 和 Link("b") 是不同元素,不會合併
Strong() 和 Strong() 如果 equality 相等,也會合併
RFC 要求 equality 必须满足 reflexive、symmetric、transitive、hash consistency,而且元素插入后不应再被外部 mutation 破坏 hash/equality。
排序规则
这是 RFC 很重要的部分。
Active set 排序
r[i].objs 的顺序不是依 hash、不是依字母、也不是依 range 长度,而是:
元素第一次被 insert 的順序
例如:
insert(Strong, 1, 10)
insert(Italic, 1, 10)
insert(Code, 1, 10)
则:
r[5].objs == [Strong, Italic, Code]
RFC 指出这样做是为了 deterministic、跨语言一致,而且符合 Markdown nesting:越早出现的 style 通常是外层。
Merge 不会改变 insertion order
例如:
insert(Strong, 1, 5) // Strong ord = 1
insert(Italic, 3, 7) // Italic ord = 2
insert(Strong, 4, 8) // Strong range 合併成 [1,8],但 ord 還是 1
查询:
r[6].objs
结果是:
[Strong, Italic]
虽然 Strong 是第三步才延伸到 index 6,但它的 first-insert order 仍然比 Italic 早。RFC 用这个 case 钉死「元素第一次出现的顺序」才是排序基准。
Transitions 排序
同一个 coordinate 上:
-
.open比.close早 -
多个
.open:依 insertion order 升序 -
多个
.close:依 insertion order 降序,也就是 LIFO
这样可以符合 Markdown stack discipline:
** open
_ open
_ close
** close
RFC 明确定义这套 tie-breaking,以避免 Ruby / Swift hash order 不一致造成跨语言输出不同。
内部资料结构
RFC 选择的核心设计是:
Map<Element, SortedList<Interval>>
+ insertion_order
+ lazy boundary-event index
+ version counter
1. Per-element sorted disjoint list
每个元素有自己的 interval list:
intervals: Map<Element, SortedList<Interval>>
而且必须维持 canonical form:
-
依
lo递增排序 -
彼此不重叠
-
彼此不相邻
-
每个 interval 都满足
lo <= hi
RFC 称这是 I1 invariant。
2. Lazy boundary-event index
Rangeable 不会每次 insert 都重建查询 index,而是等第一次 query 时才 build。
version: Int
event_index: EventIndex?
event_index 包含:
events: SortedArray<Event>
segments: SortedArray<Segment>
version: Int
这个设计是为了符合「build-once-then-query-densely」的 workload:大量 insert 完后,再密集查询每个位置。RFC 明确说明 lazy index 适合这种模式,因为 build phase 不需要一直 rebuild index,query phase 只付一次 O(M log M) 成本。
演算法重点
insert 的核心流程
RFC 的 pseudocode 大致是:
function insert(r, e, start, end):
if start > end:
raise InvalidIntervalError
e_frozen = freeze_for_insert(e)
if e not in intervals:
intervals[e] = []
insertion_order.append(e)
ord[e] = insertion_order.length
list = intervals[e]
lo = start
hi = end
找到第一個可能與 [lo, hi] 重疊或相鄰的 interval
while interval 跟 [lo, hi] 重疊或相鄰:
lo = min(lo, interval.lo)
hi = max(hi, interval.hi)
移除舊 interval
插入合併後的新 [lo, hi]
如果真的有改變:
version += 1
event_index = nil
特别要注意 RFC 提醒不能用 lo - 1 来判断,因为 lo == Int.min 时会 underflow;应该用 hi + 1 >= lo 或等价的 successor model。
复杂度
RFC 选择的 reference structure 是:
per-element sorted disjoint list + lazy event index
复杂度大致如下:
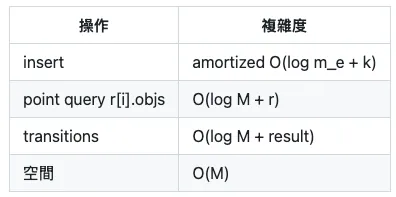
其中:
m_e = 某個 element 自己的 merged interval 數量
k = 本次 insert 吸收/合併掉的舊 intervals 數量
M = 所有 elements 的 merged intervals 總數
r = 查詢位置實際 active 的 elements 數量
RFC 也指出,如果同一个位置真的有 m 个元素 active,那输出本身就需要 Ω(m) ,所以 O(log M + m) 已经是 output-sensitive 的合理界线。
为什么不用 Interval Tree / Segment Tree / Roaring Bitmap?
RFC 有一整节比较替代方案,最后选择 (a) Per-element sorted disjoint list + lazy event index 。
重点如下:

RFC 总结选择主结构的三个原因:
-
per-element merge 语意自然,
getRange可以直接回传R(e) -
deterministic、跨语言可重现
-
lazy index 很适合 build-once-then-query workload
v1 不包含的功能
RFC 明确列出 v1 不做:
remove(e, start, end)
remove(e)
clear
union / intersect / difference
persistent immutable snapshot
floating-point coordinates
multi-dimensional rectangle stabbing
r[lo...hi].objs 這種 range slot query
删除、交集这块也请 AI 著手在 RFC V2 实现。
请 AI 基于 Rangeable RFC 实现语言实作
流程
-
一样是先走
/planPlan Mode 请 AI 详细阅读 RFC 并规划实作 -
一样拆分 developer / reviewer 一个做一个审核,直到没问题
-
撰写 Readme 使用文件、Push 到 GitHub
最困难的 RFC 规格研究已经完成后面的实作只要 AI 遵照这个规格实现,几乎都不会有问题。
目前已实现的语言如下
-
Ruby 3.2+ github.com/ZhgChgLi/RubyRangeable
-
Swift 5.7+ github.com/ZhgChgLi/SwiftRangeable
-
Python 3.10+ github.com/ZhgChgLi/PythonRangeable
-
TypeScript / JS (Node 18+) github.com/ZhgChgLi/JSRangeable
-
Kotlin / JVM 11+ github.com/ZhgChgLi/KotlinRangeable
-
Go 1.22+ github.com/ZhgChgLi/GoRangeable
实际应用 AI 设计开发的 — Rangeable Foundation
东西都准备好之后,回到最一开始的开源专案 ZMediumToMarkdown 的算法问题本身,请 AI 套用这个 Lib 回到、移除原本复杂的 walkthrough 做法优化架构+ 补上验证套用前后测试 。
ZMediumToMarkdown 3.6.0
Performance
-
Micro-benchmark: 5.5× faster on the markup render hot path.
-
End-to-end on a real Medium article: 2.23× faster (2073 µs → 930 µs per paragraph on average).
AVPlayer 本地 Cache 实作攻略
文章内容也多补充了套用 SwiftRangeable 的案例。
赞叹 AI
原本都只拿 AI 做一些应用问题,例如 重新设计网站 、 个人 Dashboard 亦或是工作上的产品问题修正;首次尝试请他深入研究解决算法、底层资料设计的问题。
效果超乎我的想像,大略阅读了他写的 RFC,不管是格式还是内容都不比真实的人去研究写出来的东西还差(至少一定比我写的好),中间有观察他在做什么,他会用 Web Search 去搜寻公开的相关论文或是技术文献然后整合评估实作合理性;拆分出 doer / reviewer 的效果也很显著,doer 会太著重在实作而 reviewer 能以更广更高的视角来纵观看 doer 做的东西有没有 side effect;最后 RFC 定下后再请 AI 基于这个文件实作,准确度几乎是 100%。
AI 使用的反思
不过大家也不用怕被 AI 取代,主要还是解决问题的思维,这个 AI 就很弱了;例如如果直接叫他去优化 ZMediumToMarkdown 他可能只能专注在 Medium 的场景还有原本程式的写法; 但是人知道可以抽成 Foundation,可以先研究 RFC,最后再实践,这样效果更好;当然我们也可以自己做,只是需要时间,AI 是帮我们加速这个过程,不是取代我们。


留言 · Comments